Enjoyed this post?
Be sure to subscribe to the nopAccelerate newsletter and get regular updates about awesome posts just like this one and more!
When search traffic spikes, indexes grow to millions of documents, and uptime becomes non-negotiable, the question isn’t “Can Solr handle it?”, it’s “Should we stay on standalone Solr or move to SolrCloud?”
This blog breaks down the core technical trade-offs so you can choose the right setup for your scaling and performance goals.
TL;DR:
Standalone Solr works best for smaller or low-complexity search environments.
SolrCloud is the evolution built for scalability, uptime, and distributed performance, the foundation of any open-source enterprise search engine that needs to grow without limits.
Apache Solr, in its standalone configuration, operates as a single-server open-source enterprise search engine.
Built on top of Apache Lucene, Solr extends Lucene’s capabilities into a fully managed search platform that offers indexing, query handling, faceted navigation, and analytics, all through RESTful APIs.
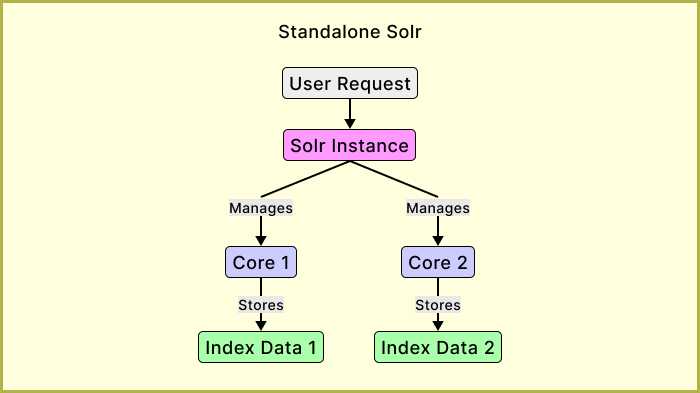
In standalone mode, Solr runs as a single node managing one or more cores, where each core represents an independent index.
Each core maintains its configuration (schema.xml, solrconfig.xml) and stores data locally. All indexing and querying operations are processed by this one server instance.
While easy to set up and maintain for moderate data volumes or testing environments, standalone Solr comes with two primary constraints:
Single Point of Failure – If the server goes down, your search service stops.
Limited Scalability – Handling very large datasets or high query loads becomes difficult, as everything depends on a single machine’s capacity.
SolrCloud is the distributed and cloud-ready deployment model of Apache Solr, designed to deliver high availability, fault tolerance, and massive scalability for enterprise environments.
It transforms a single Solr instance into a clustered, open-source enterprise search engine capable of handling huge data volumes and high query loads with consistent performance.
SolrCloud distributes both data and queries across multiple nodes for consistent performance even if one node fails.
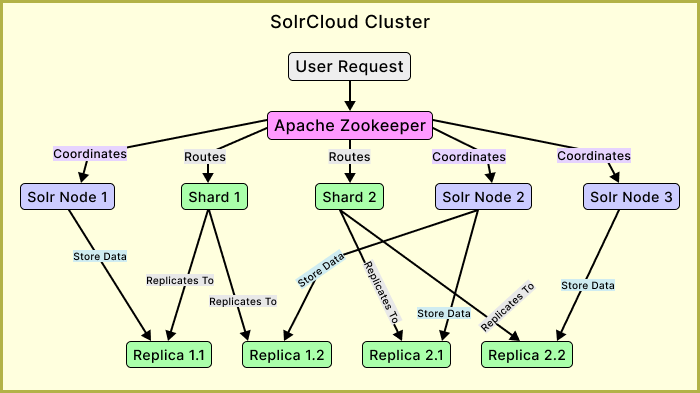
At the core of SolrCloud is the concept of collections, which represent distributed logical indexes.
Each collection is divided into shards (data partitions), and each shard has one or more replicas (copies of that data).
A leader node coordinates indexing operations for its shard, while followers serve queries to maintain speed and balance.
This coordination layer allows SolrCloud to self-heal, redistribute data dynamically, and maintain reliability across distributed environments.
SolrCloud’s distributed design ensures uninterrupted service, making it ideal for mission-critical systems that demand continuous uptime and rapid data retrieval.
While SolrCloud is essentially a distributed mode of Solr, the architectural, operational, and scalability differences between a standalone Solr setup and a SolrCloud cluster are substantial.
| Feature | Standalone Solr | SolrCloud |
| Architecture | Single-node setup, optional master–slave replication | Fully distributed, peer-to-peer architecture with centralized coordination via Apache ZooKeeper |
| Scalability | Primarily vertical scaling (add CPU, RAM, disk) | Horizontal scaling supported natively; add more nodes or shards as data grows |
| High Availability | Single point of failure, downtime if node fails | Built-in high availability using replication and automatic fail over |
| Fault Tolerance | Manual recovery required | Automatic recovery through leader election and self-healing replicas |
| Coordination & Management | Manual configuration for each instance | Centralized cluster management through ZooKeeper for config sync and state tracking |
| Configuration Files | Separate schema.xml and solrconfig.xml for each core | Configs stored centrally and shared across the cluster |
| Complexity | Easy to set up and maintain | Requires distributed setup knowledge (ZooKeeper, shards, replicas) |
| Performance Optimization | Limited to single-machine performance tuning | Load-balanced queries, distributed caching, and better resource utilization |
| Use Case Fit | Ideal for small to mid-sized deployments, testing, and learning environments | Best for large-scale enterprise, eCommerce, SaaS, and analytics platforms needing scalability and uptime |
| Data Distribution | Manual sharding (if needed) | Automatic sharding and replication across nodes |
| Cost of Operation | Lower infra cost but limited redundancy | Higher initial infra, but better long-term efficiency and reliability |
SolrCloud eliminates the manual overhead of managing multiple Solr nodes while providing resilient, scalable, and fault-tolerant performance, making it the clear choice for enterprise-scale, cloud-native deployments.
While SolrCloud delivers advanced scalability and fault tolerance, standalone Solr still holds its place for simpler, low-maintenance environments where distributed complexity isn’t justified.
It’s the right fit when speed of setup, simplicity, and resource efficiency outweigh the need for high availability.
SolrCloud becomes the natural choice once scalability, uptime, and distributed data management become business-critical.
Its clustered architecture ensures continuous availability, faster query performance, and simplified management at scale.
The difference between Solr and SolrCloud isn’t just architectural, it’s strategic.
Standalone Solr delivers simplicity and control for focused, lightweight deployments.
But when your data outgrows a single node and your uptime becomes non-negotiable, SolrCloud evolves Solr into a distributed, fault-tolerant, open-source enterprise search engine built for real-world scale.
If you’re enhancing your eCommerce search or need Solr expertise for scaling or integration, our team at nopAccelerate can help build, optimize, and manage your search infrastructure with confidence.






Leave A Comment